
Databricks Certified Associate Developer for Apache Spark 3.5 – Python
Last Update Jul 26, 2026
Total Questions : 136
We are offering FREE Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 Databricks exam questions. All you do is to just go and sign up. Give your details, prepare Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 free exam questions and then go for complete pool of Databricks Certified Associate Developer for Apache Spark 3.5 – Python test questions that will help you more.



4 of 55.
A developer is working on a Spark application that processes a large dataset using SQL queries. Despite having a large cluster, the developer notices that the job is underutilizing the available resources. Executors remain idle for most of the time, and logs reveal that the number of tasks per stage is very low. The developer suspects that this is causing suboptimal cluster performance.
Which action should the developer take to improve cluster utilization?
34 of 55.
A data engineer is investigating a Spark cluster that is experiencing underutilization during scheduled batch jobs.
After checking the Spark logs, they noticed that tasks are often getting killed due to timeout errors, and there are several warnings about insufficient resources in the logs.
Which action should the engineer take to resolve the underutilization issue?
A data scientist at a financial services company is working with a Spark DataFrame containing transaction records. The DataFrame has millions of rows and includes columns for transaction_id, account_number, transaction_amount, and timestamp. Due to an issue with the source system, some transactions were accidentally recorded multiple times with identical information across all fields. The data scientist needs to remove rows with duplicates across all fields to ensure accurate financial reporting.
Which approach should the data scientist use to deduplicate the orders using PySpark?
Given the schema:

event_ts TIMESTAMP,
sensor_id STRING,
metric_value LONG,
ingest_ts TIMESTAMP,
source_file_path STRING
The goal is to deduplicate based on: event_ts, sensor_id, and metric_value.
Options:
40 of 55.
A developer wants to refactor older Spark code to take advantage of built-in functions introduced in Spark 3.5.
The original code:
from pyspark.sql import functions as F
min_price = 110.50
result_df = prices_df.filter(F.col("price") > min_price).agg(F.count("*"))
Which code block should the developer use to refactor the code?
A Spark application is experiencing performance issues in client mode because the driver is resource-constrained.
How should this issue be resolved?
A data engineer is working on a Streaming DataFrame streaming_df with the given streaming data:
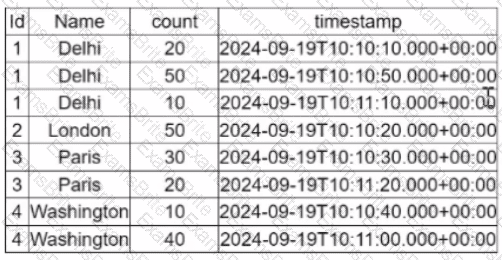
Which operation is supported with streamingdf ?
What is the benefit of using Pandas on Spark for data transformations?
Options:
33 of 55.
The data engineering team created a pipeline that extracts data from a transaction system.
The transaction system stores timestamps in UTC, and the data engineers must now transform the transaction_datetime field to the “America/New_York” timezone for reporting.
Which code should be used to convert the timestamp to the target timezone?
49 of 55.
In the code block below, aggDF contains aggregations on a streaming DataFrame:
aggDF.writeStream \
.format("console") \
.outputMode("???") \
.start()
Which output mode at line 3 ensures that the entire result table is written to the console during each trigger execution?
55 of 55.
An application architect has been investigating Spark Connect as a way to modernize existing Spark applications running in their organization.
Which requirement blocks the adoption of Spark Connect in this organization?
43 of 55.
An organization has been running a Spark application in production and is considering disabling the Spark History Server to reduce resource usage.
What will be the impact of disabling the Spark History Server in production?
41 of 55.
A data engineer is working on the DataFrame df1 and wants the Name with the highest count to appear first (descending order by count), followed by the next highest, and so on.
The DataFrame has columns:
id | Name | count | timestamp
---------------------------------
1 | USA | 10
2 | India | 20
3 | England | 50
4 | India | 50
5 | France | 20
6 | India | 10
7 | USA | 30
8 | USA | 40
Which code fragment should the engineer use to sort the data in the Name and count columns?
A data scientist is working with a Spark DataFrame called customerDF that contains customer information. The DataFrame has a column named email with customer email addresses. The data scientist needs to split this column into username and domain parts.
Which code snippet splits the email column into username and domain columns?
25 of 55.
A Data Analyst is working on employees_df and needs to add a new column where a 10% tax is calculated on the salary.
Additionally, the DataFrame contains the column age, which is not needed.
Which code fragment adds the tax column and removes the age column?
What is the risk associated with this operation when converting a large Pandas API on Spark DataFrame back to a Pandas DataFrame?
Given the code:

df = spark.read.csv("large_dataset.csv")
filtered_df = df.filter(col("error_column").contains("error"))
mapped_df = filtered_df.select(split(col("timestamp"), " ").getItem(0).alias("date"), lit(1).alias("count"))
reduced_df = mapped_df.groupBy("date").sum("count")
reduced_df.count()
reduced_df.show()
At which point will Spark actually begin processing the data?
A data engineer is reviewing a Spark application that applies several transformations to a DataFrame but notices that the job does not start executing immediately.
Which two characteristics of Apache Spark's execution model explain this behavior?
Choose 2 answers:
42 of 55.
A developer needs to write the output of a complex chain of Spark transformations to a Parquet table called events.liveLatest.
Consumers of this table query it frequently with filters on both year and month of the event_ts column (a timestamp).
The current code:
from pyspark.sql import functions as F
final = df.withColumn("event_year", F.year("event_ts")) \
.withColumn("event_month", F.month("event_ts")) \
.bucketBy(42, ["event_year", "event_month"]) \
.saveAsTable("events.liveLatest")
However, consumers report poor query performance.
Which change will enable efficient querying by year and month?
16 of 55.
A data engineer is reviewing a Spark application that applies several transformations to a DataFrame but notices that the job does not start executing immediately.
Which two characteristics of Apache Spark's execution model explain this behavior? (Choose 2 answers)
A developer needs to produce a Python dictionary using data stored in a small Parquet table, which looks like this:

The resulting Python dictionary must contain a mapping of region -> region id containing the smallest 3 region_id values.
Which code fragment meets the requirements?
A)

B)

C)

D)

The resulting Python dictionary must contain a mapping of region -> region_id for the smallest 3 region_id values.
Which code fragment meets the requirements?
45 of 55.
Which feature of Spark Connect should be considered when designing an application that plans to enable remote interaction with a Spark cluster?
A data engineer is running a batch processing job on a Spark cluster with the following configuration:
10 worker nodes
16 CPU cores per worker node
64 GB RAM per node
The data engineer wants to allocate four executors per node, each executor using four cores.
What is the total number of CPU cores used by the application?
30 of 55.
A data engineer is working on a num_df DataFrame and has a Python UDF defined as:
def cube_func(val):
return val * val * val
Which code fragment registers and uses this UDF as a Spark SQL function to work with the DataFrame num_df?
A Spark engineer is troubleshooting a Spark application that has been encountering out-of-memory errors during execution. By reviewing the Spark driver logs, the engineer notices multiple "GC overhead limit exceeded" messages.
Which action should the engineer take to resolve this issue?
A developer wants to refactor some older Spark code to leverage built-in functions introduced in Spark 3.5.0. The existing code performs array manipulations manually. Which of the following code snippets utilizes new built-in functions in Spark 3.5.0 for array operations?

A)

B)
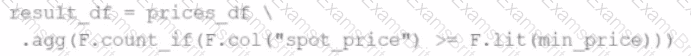
C)

D)

A data engineer uses a broadcast variable to share a DataFrame containing millions of rows across executors for lookup purposes. What will be the outcome?
44 of 55.
A data engineer is working on a real-time analytics pipeline using Spark Structured Streaming.
They want the system to process incoming data in micro-batches at a fixed interval of 5 seconds.
Which code snippet fulfills this requirement?
A data engineer is building a Structured Streaming pipeline and wants the pipeline to recover from failures or intentional shutdowns by continuing where the pipeline left off.
How can this be achieved?
An engineer has two DataFrames: df1 (small) and df2 (large). A broadcast join is used:
python
CopyEdit
from pyspark.sql.functions import broadcast
result = df2.join(broadcast(df1), on='id', how='inner')
What is the purpose of using broadcast() in this scenario?
Options:
A developer wants to test Spark Connect with an existing Spark application.
What are the two alternative ways the developer can start a local Spark Connect server without changing their existing application code? (Choose 2 answers)
Given this code:

.withWatermark("event_time", "10 minutes")
.groupBy(window("event_time", "15 minutes"))
.count()
What happens to data that arrives after the watermark threshold?
Options:
A data analyst wants to add a column date derived from a timestamp column.
Options:
2 of 55. Which command overwrites an existing JSON file when writing a DataFrame?
37 of 55.
A data scientist is working with a Spark DataFrame called customerDF that contains customer information.
The DataFrame has a column named email with customer email addresses.
The data scientist needs to split this column into username and domain parts.
Which code snippet splits the email column into username and domain columns?
9 of 55.
Given the code fragment:
import pyspark.pandas as ps
pdf = ps.DataFrame(data)
Which method is used to convert a Pandas API on Spark DataFrame (pyspark.pandas.DataFrame) into a standard PySpark DataFrame (pyspark.sql.DataFrame)?
48 of 55.
A data engineer needs to join multiple DataFrames and has written the following code:
from pyspark.sql.functions import broadcast
data1 = [(1, "A"), (2, "B")]
data2 = [(1, "X"), (2, "Y")]
data3 = [(1, "M"), (2, "N")]
df1 = spark.createDataFrame(data1, ["id", "val1"])
df2 = spark.createDataFrame(data2, ["id", "val2"])
df3 = spark.createDataFrame(data3, ["id", "val3"])
df_joined = df1.join(broadcast(df2), "id", "inner") \
.join(broadcast(df3), "id", "inner")
What will be the output of this code?

TESTED 26 Jul 2026