AWS Certified Machine Learning Engineer - Associate
Last Update Jul 18, 2026
Total Questions : 241
We are offering FREE MLA-C01 Amazon Web Services exam questions. All you do is to just go and sign up. Give your details, prepare MLA-C01 free exam questions and then go for complete pool of AWS Certified Machine Learning Engineer - Associate test questions that will help you more.



An ML engineer has developed a binary classification model outside of Amazon SageMaker. The ML engineer needs to make the model accessible to a SageMaker Canvas user for additional tuning.
The model artifacts are stored in an Amazon S3 bucket. The ML engineer and the Canvas user are part of the same SageMaker domain.
Which combination of requirements must be met so that the ML engineer can share the model with the Canvas user? (Choose two.)
A company uses an Amazon EMR cluster to run a data ingestion process for an ML model. An ML engineer notices that the processing time is increasing.
Which solution will reduce the processing time MOST cost-effectively?
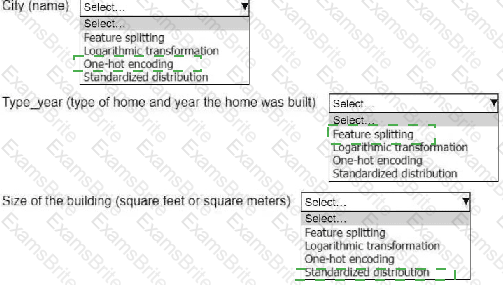
An ML engineer is working on an ML model to predict the prices of similarly sized homes. The model will base predictions on several features The ML engineer will use the following feature engineering techniques to estimate the prices of the homes:
• Feature splitting
• Logarithmic transformation
• One-hot encoding
• Standardized distribution
Select the correct feature engineering techniques for the following list of features. Each feature engineering technique should be selected one time or not at all (Select three.)

An ML engineer is setting up an Amazon SageMaker AI pipeline for an ML model. The pipeline must automatically initiate a re-training job if any data drift is detected.
How should the ML engineer set up the pipeline to meet this requirement?
An ML engineer wants to deploy an Amazon SageMaker AI model for inference. The payload sizes are less than 3 MB. Processing time does not exceed 45 seconds. The traffic patterns will be irregular or unpredictable.
Which inference option will meet these requirements MOST cost-effectively?
An ML engineer wants to use Amazon SageMaker Data Wrangler to perform preprocessing on a dataset. The ML engineer wants to use the processed dataset to train a classification model. During preprocessing, the ML engineer notices that a text feature has a range of thousands of values that differ only by spelling errors. The ML engineer needs to apply an encoding method so that after preprocessing is complete, the text feature can be used to train the model.
Which solution will meet these requirements?
A credit card company has a fraud detection model in production on an Amazon SageMaker endpoint. The company develops a new version of the model. The company needs to assess the new model ' s performance by using live data and without affecting production end users.
Which solution will meet these requirements?
A company has an ML model that needs to run one time each night to predict stock values. The model input is 3 MB of data that is collected during the current day. The model produces the predictions for the next day. The prediction process takes less than 1 minute to finish running.
How should the company deploy the model on Amazon SageMaker to meet these requirements?
An ML engineer is tuning an image classification model that performs poorly on one of two classes. The poorly performing class represents an extremely small fraction of the training dataset.
Which solution will improve the model’s performance?
A company has a custom extract, transform, and load (ETL) process that runs on premises. The ETL process is written in the R language and runs for an average of 6 hours. The company wants to migrate the process to run on AWS.
Which solution will meet these requirements?
A company wants to deploy an Amazon SageMaker AI model that can queue requests. The model needs to handle payloads of up to 1 GB that take up to 1 hour to process. The model must return an inference for each request. The model also must scale down when no requests are available to process.
Which inference option will meet these requirements?
An ML engineer is building an ML model in Amazon SageMaker AI. The ML engineer needs to load historical data directly from Amazon S3, Amazon Athena, and Snowflake into SageMaker AI.
Which solution will meet this requirement?
An ML engineer is deploying a generative AI model-based customer support agent that uses Amazon SageMaker AI for inference. The customer support agent must respond to customer questions about topics such as shipping policies, refund processes, and account management. The generative AI model generates one token at a time.
Customers report dissatisfaction with how long the customer support agent takes to generate lengthy responses to questions. The ML engineer must apply an inference optimization technique to improve the performance of the customer support agent.
Which solution will meet this requirement?
An ML engineer is collecting data to train a classification ML model by using Amazon SageMaker AI. The target column can have two possible values: Class A or Class B. The ML engineer wants to ensure that the number of samples for both Class A and Class B are balanced, without losing any existing training data. The ML engineer must test the balance of the training data.
Which solution will meet this requirement?
A gaming company needs to deploy a natural language processing (NLP) model to moderate a chat forum in a game. The workload experiences heavy usage during evenings and weekends but minimal activity during other hours.
Which solution will meet these requirements MOST cost-effectively?
A company uses Amazon SageMaker Studio to develop an ML model. The company has a single SageMaker Studio domain. An ML engineer needs to implement a solution that provides an automated alert when SageMaker AI compute costs reach a specific threshold.
Which solution will meet these requirements?
A company is developing an ML model by using Amazon SageMaker AI. The company must monitor bias in the model and display the results on a dashboard. An ML engineer creates a bias monitoring job.
How should the ML engineer capture bias metrics to display on the dashboard?
An ML engineer develops a neural network model to predict whether customers will continue to subscribe to a service. The model performs well on training data. However, the accuracy of the model decreases significantly on evaluation data.
The ML engineer must resolve the model performance issue.
Which solution will meet this requirement?
A bank needs to use Amazon SageMaker AI to create an ML model to determine which customers qualify for a new product. The bank must use algorithms that SageMaker AI directly supports. The model must be explainable to the bank ' s regulators.
Which modeling approach will meet these requirements?
A company has a binary classification model in production. An ML engineer needs to develop a new version of the model.
The new model version must maximize correct predictions of positive labels and negative labels. The ML engineer must use a metric to recalibrate the model to meet these requirements.
Which metric should the ML engineer use for the model recalibration?
A company uses a hybrid cloud environment. A model that is deployed on premises uses data in Amazon 53 to provide customers with a live conversational engine.
The model is using sensitive data. An ML engineer needs to implement a solution to identify and remove the sensitive data.
Which solution will meet these requirements with the LEAST operational overhead?
A company uses Amazon SageMaker Studio to develop an ML model. The company has a single SageMaker Studio domain. An ML engineer needs to implement a solution that provides an automated alert when SageMaker compute costs reach a specific threshold.
Which solution will meet these requirements?
A music streaming company constantly streams song ratings from an application to an Amazon S3 bucket. The company wants to use the ratings as an input for training and inference of an Amazon SageMaker AI model.
The company has an AWS Glue Data Catalog that is configured with the S3 bucket as the source. An ML engineer needs to implement a solution to create a repository for this data. The solution must ensure that the data stays synchronized during batch training and real-time inference.
Which solution will meet these requirements?
An ML engineer at a credit card company built and deployed an ML model by using Amazon SageMaker AI. The model was trained on transaction data that contained very few fraudulent transactions. After deployment, the model is underperforming.
What should the ML engineer do to improve the model’s performance?
An ML engineer has a custom container that performs k-fold cross-validation and logs an average F1 score during training. The ML engineer wants Amazon SageMaker AI Automatic Model Tuning (AMT) to select hyperparameters that maximize the average F1 score.
How should the ML engineer integrate the custom metric into SageMaker AI AMT?
A company plans to use Amazon SageMaker AI to build image classification models. The company has 6 TB of training data stored on Amazon FSx for NetApp ONTAP. The file system is in the same VPC as SageMaker AI.
An ML engineer must make the training data accessible to SageMaker AI training jobs.
Which solution will meet these requirements?
A company has deployed an XGBoost prediction model in production to predict if a customer is likely to cancel a subscription. The company uses Amazon SageMaker Model Monitor to detect deviations in the F1 score.
During a baseline analysis of model quality, the company recorded a threshold for the F1 score. After several months of no change, the model ' s F1 score decreases significantly.
What could be the reason for the reduced F1 score?
An ML engineer is training an XGBoost regression model in Amazon SageMaker AI. The ML engineer conducts several rounds of hyperparameter tuning with random grid search. After these rounds of tuning, the error rate on the test hold-out dataset is much larger than the error rate on the training dataset.
The ML engineer needs to make changes before running the hyperparameter grid search again.
Which changes will improve the model ' s performance? (Select TWO.)
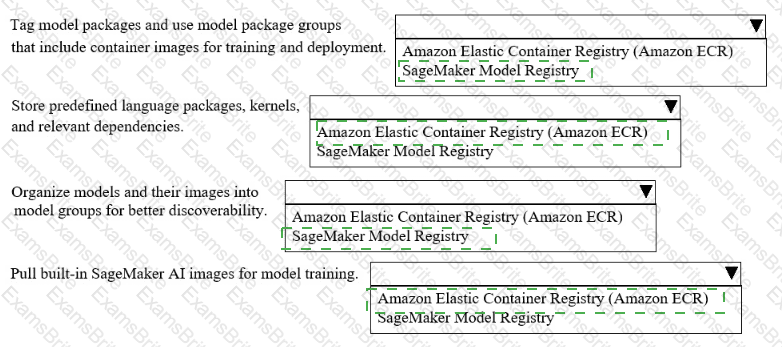
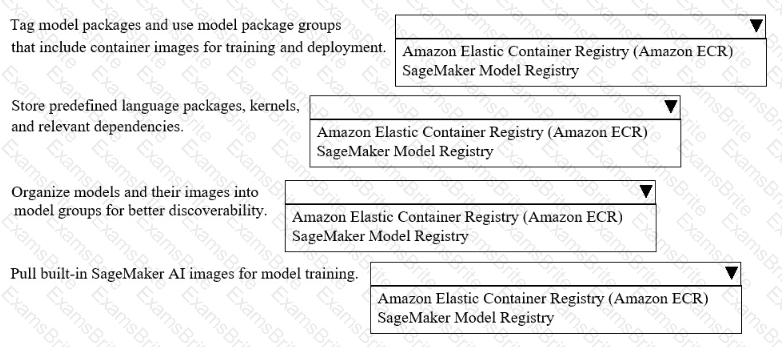
A company uses Amazon SageMakerAI to support ML workflows such as model training and deployment.
Select the correct registry from the following list to meet the requirements for each use case with the LEAST operational overhead. Each registry should be selected one or more times. (Select FOUR.)
• Amazon Elastic Container Registry (Amazon ECR)
• SageMaker Model Registry
A company is using ML to predict the presence of a specific weed in a farmer ' s field. The company is using the Amazon SageMaker linear learner built-in algorithm with a value of multiclass_dassifier for the predictorjype hyperparameter.
What should the company do to MINIMIZE false positives?
An ML engineer needs to organize a large set of text documents into topics. The ML engineer will not know what the topics are in advance. The ML engineer wants to use built-in algorithms or pre-trained models available through Amazon SageMaker AI to process the documents.
Which solution will meet these requirements?
An ML engineering team is spread across multiple locations. When the lead ML engineer opens an Amazon SageMaker AI notebook, the ML engineer does not see the latest merged notebook made by other team members from a Git repository.
The lead ML engineer must see the latest SageMaker AI notebook updates.
Which solution will meet this requirement?
An ML engineer needs to process thousands of existing CSV objects and new CSV objects that are uploaded. The CSV objects are stored in a central Amazon S3 bucket and have the same number of columns. One of the columns is a transaction date. The ML engineer must query the data based on the transaction date.
Which solution will meet these requirements with the LEAST operational overhead?
An ML engineer needs to create data ingestion pipelines and ML model deployment pipelines on AWS. All the raw data is stored in Amazon S3 buckets.
Which solution will meet these requirements?
A company uses an ML model to recommend videos to users. The model is deployed on Amazon SageMaker AI. The model performed well initially after deployment, but the model ' s performance has degraded over time.
Which solution can the company use to identify model drift in the future?
A company has deployed a model to predict the churn rate for its games by using Amazon SageMaker Studio. After the model is deployed, the company must monitor the model performance for data drift and inspect the report. Select and order the correct steps from the following list to model monitor actions. Select each step one time. (Select and order THREE.) .
Check the analysis results on the SageMaker Studio console. .
Create a Shapley Additive Explanations (SHAP) baseline for the model by using Amazon SageMaker Clarify.
Schedule an hourly model explainability monitor.

A company has a Retrieval Augmented Generation (RAG) application that uses a vector database to store embeddings of documents. The company must migrate the application to AWS and must implement a solution that provides semantic search of text files. The company has already migrated the text repository to an Amazon S3 bucket.
Which solution will meet these requirements?
A financial company receives a high volume of real-time market data streams from an external provider. The streams consist of thousands of JSON records every second.
The company needs to implement a scalable solution on AWS to identify anomalous data points.
Which solution will meet these requirements with the LEAST operational overhead?
A company has trained an ML model in Amazon SageMaker. The company needs to host the model to provide inferences in a production environment.
The model must be highly available and must respond with minimum latency. The size of each request will be between 1 KB and 3 MB. The model will receive unpredictable bursts of requests during the day. The inferences must adapt proportionally to the changes in demand.
How should the company deploy the model into production to meet these requirements?
A company has a large, unstructured dataset. The dataset includes many duplicate records across several key attributes.
Which solution on AWS will detect duplicates in the dataset with the LEAST code development?
A company wants to use large language models (LLMs) that are supported by Amazon Bedrock to develop a chat interface for the company ' s internal technical documentation. The company stores the documentation as dozens of text files that are several megabytes in total size. The company updates the text files often.
Which solution will meet these requirements MOST cost-effectively?
A company is running ML models on premises by using custom Python scripts and proprietary datasets. The company is using PyTorch. The model building requires unique domain knowledge. The company needs to move the models to AWS.
Which solution will meet these requirements with the LEAST effort?
A financial company receives a high volume of real-time market data streams from an external provider. The streams consist of thousands of JSON records per second.
The company needs a scalable AWS solution to identify anomalous data points with the LEAST operational overhead.
Which solution will meet these requirements?
A company is creating an ML model to identify defects in a product. The company has gathered a dataset and has stored the dataset in TIFF format in Amazon S3. The dataset contains 200 images in which the most common defects are visible. The dataset also contains 1,800 images in which there is no defect visible.
An ML engineer trains the model and notices poor performance in some classes. The ML engineer identifies a class imbalance problem in the dataset.
What should the ML engineer do to solve this problem?
A company regularly receives new training data from a vendor of an ML model. The vendor delivers cleaned and prepared data to the company’s Amazon S3 bucket every 3–4 days.
The company has an Amazon SageMaker AI pipeline to retrain the model. An ML engineer needs to run the pipeline automatically when new data is uploaded to the S3 bucket.
Which solution will meet these requirements with the LEAST operational effort?
An ML engineer is training a simple neural network model. The ML engineer tracks the performance of the model over time on a validation dataset. The model ' s performance improves substantially at first and then degrades after a specific number of epochs.
Which solutions will mitigate this problem? (Choose two.)
An ML engineer needs to use an ML model to predict the price of apartments in a specific location.
Which metric should the ML engineer use to evaluate the model ' s performance?
An ML engineer wants to run a training job on Amazon SageMaker AI by using multiple GPUs. The training dataset is stored in Apache Parquet format.
The Parquet files are too large to fit into the memory of the SageMaker AI training instances.
Which solution will fix the memory problem?
A company is using Amazon SageMaker and millions of files to train an ML model. Each file is several megabytes in size. The files are stored in an Amazon S3 bucket. The company needs to improve training performance.
Which solution will meet these requirements in the LEAST amount of time?
An ML engineer needs to implement a solution to host a trained ML model. The rate of requests to the model will be inconsistent throughout the day.
The ML engineer needs a scalable solution that minimizes costs when the model is not in use. The solution also must maintain the model ' s capacity to respond to requests during times of peak usage.
Which solution will meet these requirements?
A company wants to use Amazon SageMaker AI to host an ML model that runs on CPU for real-time predictions. The model has intermittent traffic during business hours and periods of no traffic after business hours.
Which hosting option will serve inference requests in the MOST cost-effective manner?
An ML engineer is setting up a CI/CD pipeline for an ML workflow in Amazon SageMaker AI. The pipeline must automatically retrain, test, and deploy a model whenever new data is uploaded to an Amazon S3 bucket. New data files are approximately 10 GB in size. The ML engineer also needs to track model versions for auditing.
Which solution will meet these requirements?
A company has an ML model that is deployed to an Amazon SageMaker AI endpoint for real-time inference. The company needs to deploy a new model. The company must compare the new model’s performance to the currently deployed model ' s performance before shifting all traffic to the new model.
Which solution will meet these requirements with the LEAST operational effort?
A company wants to develop an ML model by using tabular data from its customers. The data contains meaningful ordered features with sensitive information that should not be discarded. An ML engineer must ensure that the sensitive data is masked before another team starts to build the model.
Which solution will meet these requirements?
An ML engineer decides to use Amazon SageMaker AI automated model tuning (AMT) for hyperparameter optimization (HPO). The ML engineer requires a tuning strategy that uses regression to slowly and sequentially select the next set of hyperparameters based on previous runs. The strategy must work across small hyperparameter ranges.
Which solution will meet these requirements?
An ML engineer is using a training job to fine-tune a deep learning model in Amazon SageMaker Studio. The ML engineer previously used the same pre-trained model with a similar
dataset. The ML engineer expects vanishing gradient, underutilized GPU, and overfitting problems.
The ML engineer needs to implement a solution to detect these issues and to react in predefined ways when the issues occur. The solution also must provide comprehensive real-time metrics during the training.
Which solution will meet these requirements with the LEAST operational overhead?
An ML engineer is using Amazon SageMaker Canvas to build a custom ML model from an imported dataset. The model must make continuous numeric predictions based on 10 years of data.
Which metric should the ML engineer use to evaluate the model’s performance?
A streaming media company uses a churn risk model to assess the churn risk of its premium tier customers. Each month, the company runs an aggregation job on individual customers’ streaming data and uploads the user engagement features to an Amazon S3 bucket. The company manually re-trains the churn risk model with the user engagement data.
The current process requires manual intervention and is time-consuming. The company needs a solution that automatically re-trains the churn prediction model with the most recent data.
Which solution will meet these requirements with the SHORTEST delay?
A company is gathering audio, video, and text data in various languages. The company needs to use a large language model (LLM) to summarize the gathered data that is in Spanish.
Which solution will meet these requirements in the LEAST amount of time?
A company is developing an application that reads animal descriptions from user prompts and generates images based on the information in the prompts. The application reads a message from an Amazon Simple Queue Service (Amazon SQS) queue. Then the application uses Amazon Titan Image Generator on Amazon Bedrock to generate an image based on the information in the message. Finally, the application removes the message from SQS queue.
Which IAM permissions should the company assign to the application ' s IAM role? (Select TWO.)
A company is exploring generative AI and wants to add a new product feature. An ML engineer is making API calls from existing Amazon EC2 instances to Amazon Bedrock.
The EC2 instances are in a private subnet and must remain private during the implementation. The EC2 instances have a security group that allows access to all IP addresses in the private subnet.
What should the ML engineer do to establish a connection between the EC2 instances and Amazon Bedrock?
Case study
An ML engineer is developing a fraud detection model on AWS. The training dataset includes transaction logs, customer profiles, and tables from an on-premises MySQL database. The transaction logs and customer profiles are stored in Amazon S3.
The dataset has a class imbalance that affects the learning of the model ' s algorithm. Additionally, many of the features have interdependencies. The algorithm is not capturing all the desired underlying patterns in the data.
Which AWS service or feature can aggregate the data from the various data sources?
An ML company wants to monitor and analyze the API calls that its AWS resources make. The company has created an AWS CloudTrail log file that logs to an Amazon S3 bucket. The company has also created an organization in AWS Organizations to manage permissions across accounts.
The company needs to enable log file validation to ensure the integrity of its log files.
Which solution will meet these requirements?
A company uses an NFS-based data store to store data for ML training. Linux-based systems access the data store.
The company needs a hybrid system to make the shared data store accessible to on-premises servers and Amazon SageMaker AI notebooks that will consume the data. File locking is required for the data producers.
Which AWS storage solution will meet these requirements?
A company uses a training job on Amazon SageMaker Al to train a neural network. The job first trains a model and then evaluates the model ' s performance ag
test dataset. The company uses the results from the evaluation phase to decide if the trained model will go to production.
The training phase takes too long. The company needs solutions that can shorten training time without decreasing the model ' s final performance.
Select the correct solutions from the following list to meet the requirements for each description. Select each solution one time or not at all. (Select THREE.)
. Change the epoch count.
. Choose an Amazon EC2 Spot Fleet.
· Change the batch size.
. Use early stopping on the training job.
· Use the SageMaker Al distributed data parallelism (SMDDP) library.
. Stop the training job.

A company is building a near real-time data analytics application to detect anomalies and failures for industrial equipment. The company has thousands of IoT sensors that send data every 60 seconds. When new versions of the application are released, the company wants to ensure that application code bugs do not prevent the application from running.
Which solution will meet these requirements?
An ML engineer has trained a neural network by using stochastic gradient descent (SGD). The neural network performs poorly on the test set. The values for training loss and validation loss remain high and show an oscillating pattern. The values decrease for a few epochs and then increase for a few epochs before repeating the same cycle.
What should the ML engineer do to improve the training process?
An ML engineer wants to deploy a workflow that processes streaming IoT sensor data and periodically retrains ML models. The most recent model versions must be deployed to production.
Which service will meet these requirements?
An ML engineer needs to use AWS CloudFormation to create an ML model that an Amazon SageMaker endpoint will host.
Which resource should the ML engineer declare in the CloudFormation template to meet this requirement?
A company stores time-series data about user clicks in an Amazon S3 bucket. The raw data consists of millions of rows of user activity every day. ML engineers access the data to develop their ML models.
The ML engineers need to generate daily reports and analyze click trends over the past 3 days by using Amazon Athena. The company must retain the data for 30 days before archiving the data.
Which solution will provide the HIGHEST performance for data retrieval?
Case Study
A company is building a web-based AI application by using Amazon SageMaker. The application will provide the following capabilities and features: ML experimentation, training, a
central model registry, model deployment, and model monitoring.
The application must ensure secure and isolated use of training data during the ML lifecycle. The training data is stored in Amazon S3.
The company needs to run an on-demand workflow to monitor bias drift for models that are deployed to real-time endpoints from the application.
Which action will meet this requirement?
A company uses Amazon Athena to query a dataset in Amazon S3. The dataset has a target variable that the company wants to predict.
The company needs to use the dataset in a solution to determine if a model can predict the target variable.
Which solution will provide this information with the LEAST development effort?

TESTED 18 Jul 2026