
Databricks Certified Data Engineer Associate Exam
Last Update Jul 26, 2026
Total Questions : 230
We are offering FREE Databricks-Certified-Data-Engineer-Associate Databricks exam questions. All you do is to just go and sign up. Give your details, prepare Databricks-Certified-Data-Engineer-Associate free exam questions and then go for complete pool of Databricks Certified Data Engineer Associate Exam test questions that will help you more.



A data engineer has three tables in a Delta Live Tables (DLT) pipeline. They have configured the pipeline to drop invalid records at each table. They notice that some data is being dropped due to quality concerns at some point in the DLT pipeline. They would like to determine at which table in their pipeline the data is being dropped.
Which of the following approaches can the data engineer take to identify the table that is dropping the records?
Which of the following is a benefit of the Databricks Lakehouse Platform embracing open source technologies?
A data engineer needs to enforce row-level security on main.secure.events(region STRING, event_id STRING). Members of the account group all_regions must see all rows. All other users must see only rows where region = ' EU ' .
Which SQL sequence satisfies the requirement?
A Databricks single-task workflow fails at the last task due to an error in a notebook. The data engineer fixes the mistake in the notebook. What should the data engineer do to rerun the workflow?
In order for Structured Streaming to reliably track the exact progress of the processing so that it can handle any kind of failure by restarting and/or reprocessing, which of the following two approaches is used by Spark to record the offset range of the data being processed in each trigger?
A data engineer configures a Databricks Lakeflow Job for daily customer data processing:
Entry task: A single notebook loads raw data.
Parallel tasks:
A SQL query task performs data cleansing.
A notebook task performs feature engineering.
A pipeline task performs model updates.
Exit task: A dashboard refresh must run after all parallel tasks complete.
Requirement: Implement this dependency pattern using a DAG-based task graph.
Which task configuration ensures that all parallel tasks complete before the dashboard refresh task runs?
A data engineer works for an organization that must meet a stringent Service Level Agreement (SLA) that demands minimal runtime errors and high availability for its data processing pipelines. The data engineer wants to avoid the operational overhead of managing and tuning clusters.
Which architectural solution will meet the requirements?
A Databricks workflow fails at the last stage due to an error in a notebook. This workflow runs daily. The data engineer fixes the mistake and wants to rerun the pipeline. This workflow is very costly and time-intensive to run.
Which action should the data engineer do in order to minimise downtime and cost?
A notebook task named check_volume calculates a daily data volume and writes it to a Lakeflow Jobs task value named record_count. If the count is greater than 1 million, the job should run high_volume_pipeline; otherwise, it should run normal_pipeline.
Which control-flow feature should be used?
Which of the following must be specified when creating a new Delta Live Tables pipeline?
A data engineer is using the OPTIMIZE command on a Delta table. What happens when OPTIMIZE is run twice on the same table with the same data?
A data engineer ingests semi-structured JSON logs into a Delta table using Auto Loader with schema evolution enabled. A new string field named userAgent appears in the JSON source data.
What happens to the new userAgent field?
A single Job runs two notebooks as two separate tasks. A data engineer has noticed that one of the notebooks is running slowly in the Job’s current run. The data engineer asks a tech lead for help in identifying why this might be the case.
Which of the following approaches can the tech lead use to identify why the notebook is running slowly as part of the Job?
Which of the following statements regarding the relationship between Silver tables and Bronze tables is always true?
A data engineer is cleaning a Bronze table that receives the same customer records from multiple source systems. Duplicate rows have the same customer_id and email values but different ingestion_timestamp values. The Silver table should contain only one record for each unique combination of customer_id and email.
Which PySpark operation correctly deduplicates the records based on the business keys?
A data engineering team ingests customer transaction data from three enterprise sources: a SQL database, Amazon S3, and an Apache Kafka stream. The data must maintain lineage and support compliance audits that require access to historical snapshots.
Which Lakeflow Connect configuration satisfies both the governance and audit requirements?
A data engineer has a single-task Job that runs each morning before they begin working. After identifying an upstream data issue, they need to set up another task to run a new notebook prior to the original task.
Which of the following approaches can the data engineer use to set up the new task?
Which of the following describes a benefit of creating an external table from Parquet rather than CSV when using a CREATE TABLE AS SELECT statement?
A Python file is ready to go into production and the client wants to use the cheapest but most efficient type of cluster possible. The workload is quite small, only processing 10GBs of data with only simple joins and no complex aggregations or wide transformations.
Which cluster meets the requirement?
A data engineer is developing an ETL process based on Spark SQL. The execution fails. The data engineer checks the Spark Ul and can see the ERRORS as follows:

Which two corrective actions should the data engineer perform to resolve this issue?
Choose 2 answers - (Q) Narrow the filters in order to collect less data in the query
A data engineer has configured a Lakeflow Job that runs daily to ingest customer transaction data from a legacy relational database. The extracted data must be written directly to a Unity Catalog table and be immediately queryable through SQL. The team must also preserve data lineage.
Which action enables this ingestion with direct landing in Unity Catalog, preserved lineage, and immediate SQL query capability?
A data engineer triggers a scheduled job but finds that the new run was not executed. The run history shows that the run was skipped with a concurrency-related queue message.
Which configuration should the engineer investigate?
A global retail company sells products across multiple categories (e.g.. Electronics, Clothing) and regions (e.g.. North. South, East. West). The sales team has provided the data engineer with a PySpark dataframe named sales_df as below and the team wants the data engineer to analyze the sales data to help them make strategic decisions.
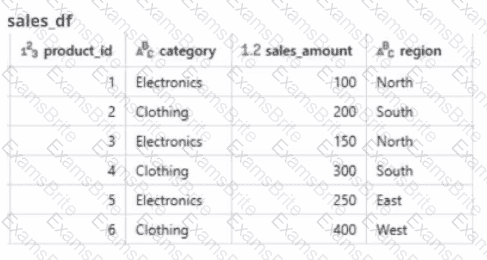
In which of the following scenarios should a data engineer select a Task in the Depends On field of a new Databricks Job Task?
A developer is building a data pipeline that processes records from a Bronze table into a Silver table. The Bronze table, bronze_events, contains duplicate records because of at-least-once delivery guarantees from the upstream ingestion system. The developer writes the following PySpark code:
deduped_df = df.dropDuplicates()
deduped_df.summary( " count " , " mean " , " stddev " ).show()
from pyspark.sql.functions import approx_count_distinct
deduped_df.select(approx_count_distinct( " user_id " )).show()
After running dropDuplicates() without arguments, some rows that differ only in the event_timestamp column remain. The developer wants to deduplicate records based only on user_id and event_type, keeping one row for each unique combination of those two columns.
Which code change achieves this deduplication requirement?
A data engineer wants to create a new table containing the names of customers who live in France.
They have written the following command:
CREATE TABLE customersInFrance
_____ AS
SELECT id,
firstName,
lastName
FROM customerLocations
WHERE country = ’FRANCE’;
A senior data engineer mentions that it is organization policy to include a table property indicating that the new table includes personally identifiable information (Pll).
Which line of code fills in the above blank to successfully complete the task?
A data engineer observes that an ETL job in Databricks has increased its execution time from a five-minute baseline to 12 minutes over the past week. Using the Lakeflow Jobs run-history view, the engineer needs to identify whether the slowdown is consistent or intermittent and determine its root cause.
Which action should the engineer take to analyze execution-time trends against the baseline?
Which SQL code snippet will correctly demonstrate a Data Definition Language (DDL) operation used to create a table?
A data engineering team has two tables. The first table march_transactions is a collection of all retail transactions in the month of March. The second table april_transactions is a collection of all retail transactions in the month of April. There are no duplicate records between the tables.
Which of the following commands should be run to create a new table all_transactions that contains all records from march_transactions and april_transactions without duplicate records?
A data engineer needs to develop integration tests for an ETL process and deploy a version-controlled, packaged workflow into production using an external job scheduler.
Which tool should the data engineer use for this job?
A Delta Live Table pipeline includes two datasets defined using streaming live table. Three datasets are defined against Delta Lake table sources using live table.
The table is configured to run in Production mode using the Continuous Pipeline Mode.
What is the expected outcome after clicking Start to update the pipeline assuming previously unprocessed data exists and all definitions are valid?
Which of the following describes the storage organization of a Delta table?
A data analysis team has noticed that their Databricks SQL queries are running too slowly when connected to their always-on SQL endpoint. They claim that this issue is present when many members of the team are running small queries simultaneously. They ask the data engineering team for help. The data engineering team notices that each of the team’s queries uses the same SQL endpoint.
Which of the following approaches can the data engineering team use to improve the latency of the team’s queries?
Which of the following data lakehouse features results in improved data quality over a traditional data lake?
A company is collaborating with a partner that does not use Databricks but needs access to a large historical dataset stored in Delta format. The data engineer needs to ensure that the partner can access the data securely, without the need for them to set up an account, and with read-only access.
How should the data be shared?
A data engineer has developed a data pipeline to ingest data from a JSON source using Auto Loader, but the engineer has not provided any type inference or schema hints in their pipeline. Upon reviewing the data, the data engineer has noticed that all of the columns in the target table are of the string type despite some of the fields only including float or boolean values.
Which of the following describes why Auto Loader inferred all of the columns to be of the string type?
A data engineer has a Declarative Automation Bundle with a job resource keyed as etl_job in databricks.yml. After running databricks bundle deploy, the job appears in the workspace but has not executed.
Which command triggers execution of the deployed job?
Which of the following commands will return the location of database customer360?
A data engineer wants to schedule their Databricks SQL dashboard to refresh every hour, but they only want the associated SQL endpoint to be running when It is necessary. The dashboard has multiple queries on multiple datasets associated with it. The data that feeds the dashboard is automatically processed using a Databricks Job.
Which approach can the data engineer use to minimize the total running time of the SQL endpoint used in the refresh schedule of their dashboard?
A data engineer runs a statement every day to copy the previous day’s sales into the table transactions. Each day’s sales are in their own file in the location " /transactions/raw " .
Today, the data engineer runs the following command to complete this task:

After running the command today, the data engineer notices that the number of records in table transactions has not changed.
Which of the following describes why the statement might not have copied any new records into the table?
A data engineer wants to create a new table containing the names of customers that live in France.
They have written the following command:

A senior data engineer mentions that it is organization policy to include a table property indicating that the new table includes personally identifiable information (PII).
Which of the following lines of code fills in the above blank to successfully complete the task?
A data engineer uses the Databricks workspace UI with Unity Catalog enabled. In Catalog Explorer, they select catalog corp_marketing, then schema campaigns, and see table email_stats. The engineer must let the growth-analysts group read email_stats from its SQL warehouses, but not create, alter, or delete any objects in corp_marketing or campaigns.
Which action sequence meets the requirement?
An organization is building a data lakehouse and needs to ingest data from multiple sources into Unity Catalog-managed tables:
Salesforce: More than 50 objects, frequent schema changes, and OAuth authentication
An on-premises SQL Server database: More than 100 tables, CDC enabled, and private network connectivity required
Daily JSON files landing in Azure Data Lake Storage Gen2
The organization wants all ingested data governed by Unity Catalog, minimal engineering effort for schema changes, and serverless processing wherever possible.
Which ingestion strategy meets these requirements?
A data engineer is working on a personal laptop and needs to perform complex transformations on data stored in a Delta Lake on cloud storage. The engineer decides to use Databricks Connect to interact with Databricks clusters and work in their local IDE.
How does Databricks Connect enable the engineer to develop, test, and debug code seamlessly on their local machine while interacting with Databricks clusters?
An engineering manager uses a Databricks SQL query to monitor ingestion latency for each data source. The manager checks the results of the query every day, but they are manually rerunning the query each day and waiting for the results.
Which of the following approaches can the manager use to ensure the results of the query are updated each day?
In which of the following scenarios should a data engineer use the MERGE INTO command instead of the INSERT INTO command?
A data engineer has been provided a PySpark DataFrame named df with columns product and revenue. The data engineer needs to compute complex aggregations to determine each product ' s total revenue, average revenue, and transaction count.
Which code snippet should the data engineer use?
A)
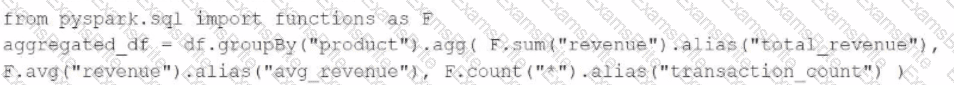
B)

C)

D)

A data engineer is preparing a Declarative Automation Bundle, formerly known as a Databricks Asset Bundle, to deploy a Lakeflow pipeline.
To ensure that the pipeline is deployed to the correct environment, where should workspace-specific configurations, such as the workspace host URL and root storage path, be defined within the bundle project?
A data engineering team needs to incrementally ingest customer transactions from a SaaS application into the Databricks Data Intelligence Platform with the following capabilities:
Built-in change data capture, including updates and deletes
Automatic schema evolution
Serverless execution with retries and minimal maintenance
OAuth support and basic monitoring
Which solution meets all the requirements?
A data engineer needs to create a table in Databricks using data from a CSV file at location /path/to/csv.
They run the following command:

Which of the following lines of code fills in the above blank to successfully complete the task?
Which of the following SQL keywords can be used to convert a table from a long format to a wide format?
An organization has implemented a data pipeline in Databricks and needs to ensure it can scale automatically based on varying workloads without manual cluster management. The goal is to meet the company’s Service Level Agreements (SLAs), which require high availability and minimal downtime, while Databricks automatically handles resource allocation and optimization.
Which approach fulfills these requirements?
A data engineer and data analyst are working together on a data pipeline. The data engineer is working on the raw, bronze, and silver layers of the pipeline using Python, and the data analyst is working on the gold layer of the pipeline using SQL. The raw source of the pipeline is a streaming input. They now want to migrate their pipeline to use Delta Live Tables.
Which of the following changes will need to be made to the pipeline when migrating to Delta Live Tables?
What are the transformations typically included in building the Bronze layer ?
Which of the following benefits is provided by the array functions from Spark SQL?
A data engineer runs df.toPandas() on a wide DataFrame containing 50 million rows. The notebook cell fails with a java.lang.OutOfMemoryError on the driver.
Which memory configuration is directly associated with this failure?
An organization is looking for an optimized storage layer that supports ACID transactions and schema enforcement. Which technology should the organization use?
Which compute option should be chosen in a scenario where small-scale ad hoc Python scripts need to be run at high frequency and should wind down quickly after these queries have finished running?
A data engineer is managing a data pipeline in Databricks, where multiple Delta tables are used for various transformations. The team wants to track how data flows through the pipeline, including identifying dependencies between Delta tables, notebooks, jobs, and dashboards. The data engineer is utilizing the Unity Catalog lineage feature to monitor this process.
How does Unity Catalog’s data lineage feature support the visualization of relationships between Delta tables, notebooks, jobs, and dashboards?
A data engineer needs to process SQL queries on a large dataset with fluctuating workloads. The workload requires automatic scaling based on the volume of queries, without the need to manage or provision infrastructure. The solution should be cost-efficient and charge only for the compute resources used during query execution.
Which compute option should the data engineer use?
Which SQL keyword can be used to convert a table from a long format to a wide format?
A data engineer at a company that uses Databricks with Unity Catalog needs to share a collection of tables with an external partner who also uses a Databricks workspace enabled for Unity Catalog. The data engineer decides to use Delta Sharing to accomplish this.
What is the first piece of information the data engineer should request from the external partner to set up Delta Sharing?
A data engineer is decommissioning a sandbox schema in Unity Catalog. Some tables are ephemeral staging outputs that can be safely removed entirely, but a few tables point at shared cloud storage used by downstream jobs outside Databricks. The engineer must avoid deleting any shared files when cleaning up catalog objects.
How does Unity Catalog behave when dropping Managed vs External tables?
A data engineer is attempting to write Python and SQL in the same command cell and is running into an error The engineer thought that it was possible to use a Python variable in a select statement.
Why does the command fail?
A data engineer is onboarding a new Bronze ingestion pipeline in Databricks with Unity Catalog. The team wants Databricks to handle storage layout, apply platform optimizations over time, and simplify lifecycle management so that when a table is dropped, its underlying data is also cleaned up according to Databricks-managed retention policies.
Which table type should the data engineer create for these ingestion tables?

TESTED 26 Jul 2026