
SnowPro Advanced: Architect Certification Exam
Last Update Jul 14, 2026
Total Questions : 182
We are offering FREE ARA-C01 Snowflake exam questions. All you do is to just go and sign up. Give your details, prepare ARA-C01 free exam questions and then go for complete pool of SnowPro Advanced: Architect Certification Exam test questions that will help you more.



What integration object should be used to place restrictions on where data may be exported?
A company is following the Data Mesh principles, including domain separation, and chose one Snowflake account for its data platform.
An Architect created two data domains to produce two data products. The Architect needs a third data domain that will use both of the data products to create an aggregate data product. The read access to the data products will be granted through a separate role.
Based on the Data Mesh principles, how should the third domain be configured to create the aggregate product if it has been granted the two read roles?
Why does a conditional multi-table insert option support the Data Vault data model?
An Architect is designing partitioned external tables for a Snowflake data lake. The data lake size may grow over time, and partition definitions may need to change in the future.
How can these requirements be met?
An Architect is designing a solution that will be used to process changed records in an orders table. Newly-inserted orders must be loaded into the f_orders fact table, which will aggregate all the orders by multiple dimensions (time, region, channel, etc.). Existing orders can be updated by the sales department within 30 days after the order creation. In case of an order update, the solution must perform two actions:
1. Update the order in the f_0RDERS fact table.
2. Load the changed order data into the special table ORDER _REPAIRS.
This table is used by the Accounting department once a month. If the order has been changed, the Accounting team needs to know the latest details and perform the necessary actions based on the data in the order_repairs table.
What data processing logic design will be the MOST performant?
Company A would like to share data in Snowflake with Company B. Company B is not on the same cloud platform as Company A.
What is required to allow data sharing between these two companies?
A global company needs to securely share its sales and Inventory data with a vendor using a Snowflake account.
The company has its Snowflake account In the AWS eu-west 2 Europe (London) region. The vendor's Snowflake account Is on the Azure platform in the West Europe region. How should the company's Architect configure the data share?
Which SQL ALTER command will MAXIMIZE memory and compute resources for a Snowpark stored procedure when executed on the snowpark_opt_wh warehouse?
A company is storing large numbers of small JSON files (ranging from 1-4 bytes) that are received from IoT devices and sent to a cloud provider. In any given hour, 100,000 files are added to the cloud provider.
What is the MOST cost-effective way to bring this data into a Snowflake table?
A company’s daily Snowflake workload consists of a huge number of concurrent queries triggered between 9pm and 11pm. At the individual level, these queries are smaller statements that get completed within a short time period.
What configuration can the company’s Architect implement to enhance the performance of this workload? (Choose two.)
A company is using Snowflake in Azure in the Netherlands. The company analyst team also has data in JSON format that is stored in an Amazon S3 bucket in the AWS Singapore region that the team wants to analyze.
The Architect has been given the following requirements:
1. Provide access to frequently changing data
2. Keep egress costs to a minimum
3. Maintain low latency
How can these requirements be met with the LEAST amount of operational overhead?
An Architect needs to design a Snowflake account and database strategy to store and analyze large amounts of structured and semi-structured data. There are many business units and departments within the company. The requirements are scalability, security, and cost efficiency.
What design should be used?
An Architect needs to grant a group of ORDER_ADMIN users the ability to clean old data in an ORDERS table (deleting all records older than 5 years), without granting any privileges on the table. The group’s manager (ORDER_MANAGER) has full DELETE privileges on the table.
How can the ORDER_ADMIN role be enabled to perform this data cleanup, without needing the DELETE privilege held by the ORDER_MANAGER role?
When loading data into a table that captures the load time in a column with a default value of either CURRENT_TIME () or CURRENT_TIMESTAMP() what will occur?
The diagram shows the process flow for Snowpipe auto-ingest with Amazon Simple Notification Service (SNS) with the following steps:
Step 1: Data files are loaded in a stage.
Step 2: An Amazon S3 event notification, published by SNS, informs Snowpipe — by way of Amazon Simple Queue Service (SQS) - that files are ready to load. Snowpipe copies the files into a queue.
Step 3: A Snowflake-provided virtual warehouse loads data from the queued files into the target table based on parameters defined in the specified pipe.
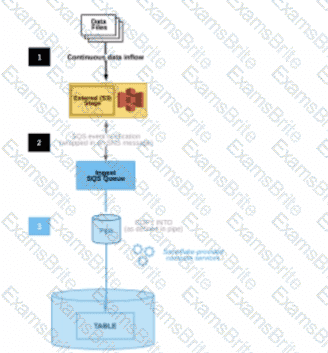
If an AWS Administrator accidentally deletes the SQS subscription to the SNS topic in Step 2, what will happen to the pipe that references the topic to receive event messages from Amazon S3?
An Architect needs to meet a company requirement to ingest files from the company's AWS storage accounts into the company's Snowflake Google Cloud Platform (GCP) account. How can the ingestion of these files into the company's Snowflake account be initiated? (Select TWO).
A.
Configure the client application to call the Snowpipe REST endpoint when new files have arrived in Amazon S3 storage.
B.
Configure the client application to call the Snowpipe REST endpoint when new files have arrived in Amazon S3 Glacier storage.
C.
Create an AWS Lambda function to call the Snowpipe REST endpoint when new files have arrived in Amazon S3 storage.
D.
Configure AWS Simple Notification Service (SNS) to notify Snowpipe when new files have arrived in Amazon S3 storage.
E.
Configure the client application to issue a COPY INTO








