
CertNexus Certified Artificial Intelligence Practitioner (CAIP)
Last Update Jul 26, 2026
Total Questions : 92
We are offering FREE AIP-210 CertNexus exam questions. All you do is to just go and sign up. Give your details, prepare AIP-210 free exam questions and then go for complete pool of CertNexus Certified Artificial Intelligence Practitioner (CAIP) test questions that will help you more.



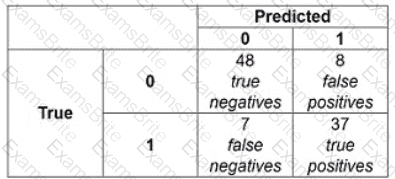
The following confusion matrix is produced when a classifier is used to predict labels on a test dataset. How precise is the classifier?
Which of the following describes a neural network without an activation function?
Which of the following tools would you use to create a natural language processing application?
Which of the following items should be included in a handover to the end user to enable them to use and run a trained model on their own system? (Select three.)
Which two encodes can be used to transform categories data into numerical features? (Select two.)
What is the primary benefit of the Federated Learning approach to machine learning?
A classifier has been implemented to predict whether or not someone has a specific type of disease. Considering that only 1% of the population in the dataset has this disease, which measures will work the BEST to evaluate this model?
A classifier has been implemented to predict whether or not someone has a specific type of disease. Considering that only 1% of the population in the dataset has this disease, which measures will work the BEST to evaluate this model?
A market research team has ratings from patients who have a chronic disease, on several functional, physical, emotional, and professional needs that stay unmet with the current therapy. The dataset also captures ratings on how the disease affects their day-to-day activities.
A pharmaceutical company is introducing a new therapy to cure the disease and would like to design their marketing campaign such that different groups of patients are targeted with different ads. These groups should ideally consist of patients with similar unmet needs.
Which of the following algorithms should the market research team use to obtain these groups of patients?
Which of the following describes a benefit of machine learning for solving business problems?
Personal data should not be disclosed, made available, or otherwise used for purposes other than specified with which of the following exceptions? (Select two.)
A dataset can contain a range of values that depict a certain characteristic, such as grades on tests in a class during the semester. A specific student has so far received the following grades: 76,81, 78, 87, 75, and 72. There is one final test in the semester. What minimum grade would the student need to achieve on the last test to get an 80% average?
Which database is designed to better anticipate and avoid risks of AI systems causing safety, fairness, or other ethical problems?
Which of the following can benefit from deploying a deep learning model as an embedded model on edge devices?
Which of the following text vectorization methods is appropriate and correctly defined for an English-to-Spanish translation machine?
Which two encoders can be used to transform categorical data into numerical features? (Select two.)
An HR solutions firm is developing software for staffing agencies that uses machine learning.
The team uses training data to teach the algorithm and discovers that it generates lower employability scores for women. Also, it predicts that women, especially with children, are less likely to get a high-paying job.
Which type of bias has been discovered?
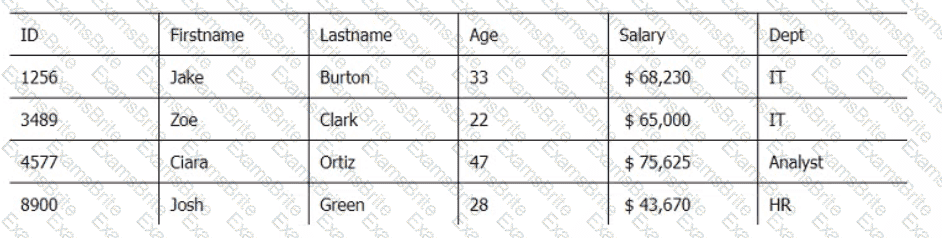
Below are three tables: Employees, Departments, and Directors.
Employee_Table
Department_Table
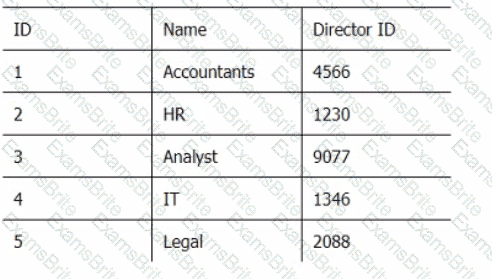
Director_Table
ID
Firstname
Lastname
Age
Salary
DeptJD
4566
Joey
Morin
62
$ 122,000
1
1230
Sam
Clarck
43
$ 95,670
2
9077
Lola
Russell
54
$ 165,700
3
1346
Lily
Cotton
46
$ 156,000
4
2088
Beckett
Good
52
$ 165,000
5
Which SQL query provides the Directors' Firstname, Lastname, the name of their departments, and the average employee's salary?
A change in the relationship between the target variable and input features is
Which of the following scenarios is an example of entanglement in ML pipelines?
A product manager is designing an Artificial Intelligence (AI) solution and wants to do so responsibly, evaluating both positive and negative outcomes.
The team creates a shared taxonomy of potential negative impacts and conducts an assessment along vectors such as severity, impact, frequency, and likelihood.
Which modeling technique does this team use?
Which of the following models are text vectorization methods? (Select two.)
In a self-driving car company, ML engineers want to develop a model for dynamic pathing. Which of following approaches would be optimal for this task?
You are developing a prediction model. Your team indicates they need an algorithm that is fast and requires low memory and low processing power. Assuming the following algorithms have similar accuracy on your data, which is most likely to be an ideal choice for the job?
Which of the following sentences is true about model evaluation and model validation in ML pipelines?
Which of the following is the primary purpose of hyperparameter optimization?
Which three security measures could be applied in different ML workflow stages to defend them against malicious activities? (Select three.)

TESTED 26 Jul 2026